What started out as a side project less than two years ago is growing up and moving into its own organization on GitHub!
The tremendous growth we have seen would not have been possible without partner contributors, and with this move TF Encrypted is being cemented as an independent community project that can encourage participation and remain focused on its mission: getting privacy-enhancing tools into the hands of machine learning practitioners.
This is a cross-posting of work done at Dropout Labs. A big thank you to Gavin Uhma, Ian Livingstone, Jason Mancuso, and Matt Maclellan for help with this post.
A Framework for Encrypted Deep Learning
TF Encrypted makes it easy to apply machine learning to data that remains encrypted at all times. It builds on, and integrates heavily, with TensorFlow, providing a familiar interface and encouraging mixing ordinary and encrypted computations. Together this ensures a pragmatic and gradual approach to a maturing technology.
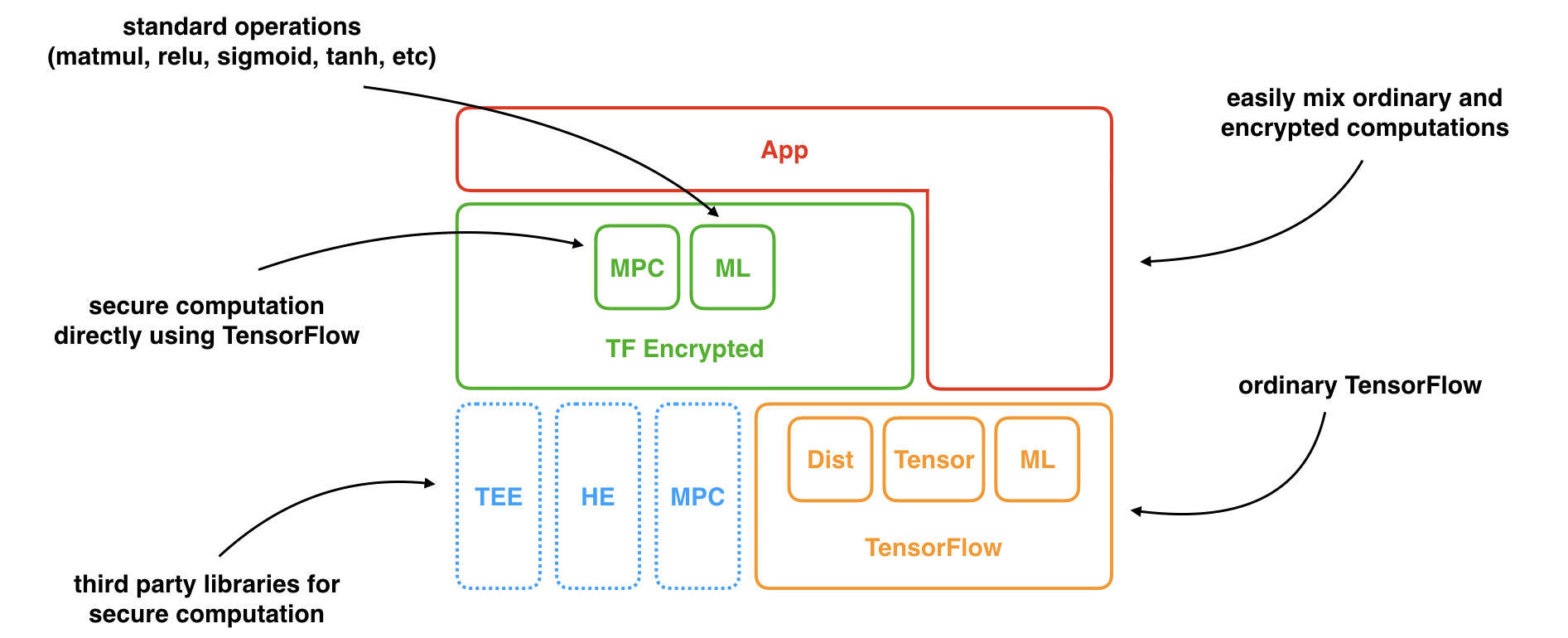
The core consists of secure computation optimized for deep learning, as well as standard deep learning components adapted to work more efficiently on encrypted data. However, the whole purpose is to abstract all of this away.
As an example, the following code snippet shows how one can serve predictions on encrypted inputs, in this case using a small neural network. It closely resembles traditional TensorFlow code, with the exception of tfe.define_private_input and tfe.define_output that are used to express our desired privacy policy: that only the client should be able to see the input and the result in plaintext, and everyone else must only see them in an encrypted state.
import tensorflow as tf
import tf_encrypted as tfe
def provide_weights(): """Load model weight from disk using TensorFlow."""
def provide_input(): """Load and preprocess input data locally on the client."""
def receive_output(logits): return tf.print(tf.argmax(logits))
w0, b0, w1, b1, w2, b2 = provide_weights()
# run provide_input locally on the client and encrypt
x = tfe.define_private_input("prediction-client", provide_input)
# compute prediction on the encrypted input
layer0 = tfe.relu(tfe.matmul(x, w0) + b0)
layer1 = tfe.relu(tfe.matmul(layer0, w1) + b1)
logits = tfe.matmul(layer1, w2) + b2
# send results back to client, decrypt, and run receive_output locally
prediction_op = tfe.define_output("prediction-client", receive_output, logits)
with tfe.Session() as sess:
sess.run(prediction_op)
Below we can see that TF Encrypted is also a natural fit for secure aggregation in federated learning. Here, in each iteration, gradients are computed locally by data owners using ordinary TensorFlow. They are then given as encrypted inputs to a secure computation of their mean, which in turn is revealed to the model owner who updates the model.
# compute and collect all model gradients as private inputs
model_grads = zip(*[
tfe.define_private_input(
data_owner.player_name,
data_owner.compute_gradient)
for data_owner in data_owners
])
# compute mean gradient securely
aggregated_model_grads = [
tfe.add_n(grads) / len(grads)
for grads in model_grads
]
# reveal only aggregated gradients to model owner
iteration_op = tfe.define_output(
model_owner.player_name,
model_owner.update_model,
aggregated_model_grads)
with tfe.Session() as sess:
for _ in range(num_iterations):
sess.run(iteration_op)
Because of tight integration with TensorFlow, this process can easily be profiled and visualized using TensorBoard, as shown in the full example.
Finally, is it also possible to perform encrypted training on joint data sets. In the snippet below, two data owners provide encrypted training data that is merged and subsequently used as any other data set.
x_train_0, y_train_0 = tfe.define_private_input(
data_owner_0.player_name,
data_owner_0.provide_training_data)
x_train_1, y_train_1 = tfe.define_private_input(
data_owner_1.player_name,
data_owner_1.provide_training_data)
x_train = tfe.concat([x_train_0, x_train_1], axis=0)
y_train = tfe.concat([y_train_0, y_train_1], axis=0)
The GitHub repository contains several more examples, including notebooks to help you get started.
Moving Forward as a Community
Since the beginning, the motivation behind TF Encrypted has been to explore and unlock the impact of privacy-preserving machine learning; and the approach taken is to help practitioners get their hands dirty and experiment.
A sub-goal of this is to help improve communication between people within different areas of expertise, including creating a common vocabulary for more efficient knowledge sharing.
To really scale this up we need to bring as many people as possible together, as this means a better collective understanding, more exploration, and more identified use cases. And the only natural place for this to happen is where you feel comfortable and encouraged to contribute.
Use cases under constraints
Getting data scientists involved is key, as the technology has reached a maturity where it can be applied to real-world problems, yet is still not ready to simply be treated as a black box; even for solving problems that on paper may otherwise seem like a perfect fit.
Instead, to further bring the technology out from research circles, and find the right use cases given current constraints, we need people with domain knowledge to benchmark on the problems they face, and report on their findings.
Helping them get started quickly, and reducing their learning curve, is a key goal of TF Encrypted.
Cross-disciplinary research
At the same time, it is important that the runtime performance of the underlying technology continues to improve, as this makes more use cases practical.
The most obvious way of doing that is for researchers in cryptography to continue the development of secure computation and its adaptation to deep learning. However, this currently requires them to gain an intuition into machine learning that most do not have.
Orthogonal to improving how the computations are performed, another direction is to improve what functions are computed. This means adapting machine learning models to the encrypted setting and essentially treating it as a new type of computing device with its own characteristics; for which some operations, or even model types, are more suitable. However, this currently requires an understanding of cryptography that most do not have.
Forming a bridge that helps these two fields collaborate, yet stay focused on their area of expertise, is another key goal of TF Encrypted.
Common platform
Frameworks like TensorFlow have shown the benefits of bringing practitioners together on the same software platform. It makes everything concrete, including vocabulary, and shortens the distance from research to application. It makes everyone move towards the same target, yet via good abstractions allows each to focus on what they do best while still benefiting from the contributions of others. In other words, it facilitates taking a modular approach to the problem, lowering the overhead of everyone first developing expertise across all domains.
All of this leads to the core belief behind TF Encrypted: that we can push the field of privacy-preserving machine learning forward by building a common and integrated platform that makes tools and techniques for encrypted deep learning easily accessible.
To do this we welcome partners and contributors from all fields, including companies that want to leverage the accumulated expertise while keeping their focus on all the remaining questions around for instance taking this all the way to production.
Challenges and Roadmap
Building the current version of TF Encrypted was only the first step, with many interesting challenges on the road ahead. Below are a select few with more up-to-date status in the GitHub issues.
High-level API
As seen earlier, the interface of TF Encrypted has so far been somewhat low-level, roughly matching that of TensorFlow 1.x. This ensured user familiarity and gave us a focal point for adapting and optimizing cryptographic techniques.
However, it also has shortcomings.
One is that expressing models in this way has simply become outdated in light of high-level APIs such as Keras. This is also evident in the upcoming TensorFlow 2.x which fully embraces Keras and similar abstractions.
The second is related to why Keras has likely become so popular, namely its ability to express complex models succinctly and closely to how we think about them. This management of complexity only becomes more relevant when you add notions of distributed data with explicit ownership and privacy policies.
Thirdly, with a low-level API it is easy for users to shoot themselves in the foot and accidentally use operations that are very expensive in the encrypted space. Obtaining good results and figuring out which cryptographic techniques work best for a particular model typically requires some expertise, yet with a low-level API it is hard to incorporate and distribute such knowledge.
As a way of mitigating these issues, we are adding a high-level API to TF Encrypted closely matching Keras, but extended to work nicely with the concepts and constraints inherent in privacy-preserving machine learning. Although still a work in progress, one might imagine rewriting the first example from above as follows.
import tensorflow as tf
import tf_encrypted as tfe
class PredictionClient:
@tfe.private_input
def provide_input(self):
"""Load and preprocess input data."""
@tfe.private_output
def receive_output(self, logits):
return tf.print(tf.argmax(logits))
model = tfe.keras.models.Sequential([
tfe.keras.layers.Dense(activation='relu'),
tfe.keras.layers.Dense(activation='relu'),
tfe.keras.layers.Dense(activation=None)
])
prediction_client = PredictionClient()
x = prediction_client.provide_input()
y = model.predict(x)
prediction_client.receive_output(y)
We believe that distilling concepts in this way will improve the ability to accumulate knowledge while retaining a large degree of flexibility.
Pre-trained models
Taking the above mindset further, we also want to encourage the use of pre-trained models and fine-tuning when possible. These provide the least flexibility for users but offer great ways for accumulating expertise and lower user investments.
We plan on providing several well-known models adapted to the encrypted space, thus offering good trade-offs between accuracy and speed.
Tighter TensorFlow integration
Being in the TensorFlow ecosystem has been a huge advantage, providing not only the familiarity and hybrid approach already mentioned, but also allowing us to benefit from an efficient distributed platform with extensive support tools.
As such, it is no surprise that we want full support for one of the most exciting changes coming with TensorFlow 2.x, and the improvements to debugging and exploration that comes with it: eager evaluation by default. While completely abandoning static dataflow graphs would likely have a significant impact on performance, we expect to find reasonable compromises through the new tf.function and static sub-components.
We are also very excited to explore how TF Encrypted can work together with other projects such as TensorFlow Federated and TensorFlow Privacy by adding secure computation to the mix. For instance, TF Encrypted can be used to realize secure aggregation for the former, and can provide a complementary approach to privacy with respect to the latter.
More cryptographic techniques
TF Encrypted has been focused almost exclusively on secure computation based on secret sharing up until this point. However, in certain scenarios and models there are several other techniques that fit more naturally or offer better performance.
We are keen on incorporating these by providing wrappers of some of the excellent projects that already exist, making it easier to experiment and benchmark various combinations of techniques and parameters, and define good defaults.
Push the boundaries
Most research on encrypted deep learning has so far focused on relatively simple models, typically with fewer than a handful of layers.
Moving forward, we need to move beyond toy-like examples and tackle more models commonly used in real-world image analysis and in other domains such as natural language processing. Having the community settle on a few such models will help increase outside interest and bring the field forward by providing a focal point for research.
Data science workflow
While some constraints are currently due to technical maturity, others seem inherent from the fact we now want to keep data private. In other words, even if we had perfect secure computation, with the same performance and scalability properties as plaintext, then we still need to figure out and potentially adapt how we do e.g. data exploration, feature engineering, and production monitoring in the encrypted space.
This area remains largely unexplored and we are excited about digging in further.
Conclusion
Having seen TF Encrypted grow and create interest over the past two years has been an amazing experience, and it is only becoming increasingly clear that the best way to push the field of privacy-preserving machine learning forward is to bring together practitioners from different domains.
As a result, development of the project is now officially by The TF Encrypted Authors with specific attribution given via the Git commit history. For situations where someone needs to take the final decision I remain benevolent dictator, working towards the core beliefs outlined here.
Learn more and become part of the development on GitHub! 🚀