Inspired by a recent blog post about mixing deep learning and homomorphic encryption (see Building Safe A.I.) I thought it’d be interesting do to the same using secure multi-party computation instead of homomorphic encryption.
In this blog post we’ll build a simple secure computation protocol from scratch, and experiment with it for training simple neural networks for basic boolean functions. There is also a Python notebook with the associated source code.
We will assume that we have three non-colluding parties P0, P1, and P2 that are willing to perform computations together, namely training neural networks and using them for predictions afterwards; however, for unspecified reasons they do not wish to reveal the learned models. We will also assume that some users are willing to provide training data if it is kept private, and likewise that some are interested in using the learned models if their inputs are kept private.
To be able to do this we will need to compute securely on rational numbers with a certain precision; in particular, to add and multiply these. We will also need to compute the Sigmoid function 1/(1+np.exp(-x)), which in its traditional form results in surprisingly heavy operations in the secure setting. As a result we’ll follow the approach of Building Safe A.I. and approximate it using polynomials, yet look at a few optimizations.
This post also exist in Chinese thanks to Jakukyo Friel.
Secure Multi-Party Computation
Homomorphic encryption (HE) and secure multi-party computation (MPC) are closely related fields in modern cryptography, with one often using techniques from the other in order to solve roughly the same problem: computing a function of private input data without revealing anything, except (optionally) the final output. For instance, in our setting of private machine learning, both technologies could be used to train our model and perform predictions (although there are a few technicalities to deal with in the case of HE if the data comes from several users with different encryption keys).
As such, at a high level, HE is often replaceable by MPC, and vice versa. Where they differ however, at least today, can roughly be characterized by HE requiring little interaction but expensive computation, whereas MPC uses cheap computation but a significant amount of interaction. Or in other words, MPC replaces expensive computation with interaction between two or more parties.
This currently offers better practical performance, to the point where one can argue that MPC is a significantly more mature technology – as a testimony to that claim, several companies already exist offering services based on MPC.
Fixed-point arithmetic
The computation is going to take place over a finite field and hence we first need to decide on how to represent rational numbers r as field elements, i.e. as integers x from 0, 1, ..., Q-1 for some prime Q. Taking a typical approach, we’re going to scale every rational number by a constant corresponding to a fixed precision, say 10**6 in the case of 6 digit precision, and let the integer part of the result be our fixed-point presentation. For instance, with Q = 10000019 we get encode(0.5) == 500000 and encode(-0.5) == 10000019 - 500000 == 9500019.
def encode(rational):
upscaled = int(rational * 10**6)
field_element = upscaled % Q
return field_element
def decode(field_element):
upscaled = field_element if field_element <= Q/2 else field_element - Q
rational = upscaled / 10**6
return rational
Note that addition in this representation is straight-forward, (r * 10**6) + (s * 10**6) == (r + s) * 10**6, while multiplication adds an extra scaling factor that we will have to get rid of to keep the precision and avoid exploding the numbers: (r * 10**6) * (s * 10**6) == (r * s) * 10**6 * 10**6.
Sharing and reconstructing data
Having encoded an input, each user next needs a way of sharing it with the parties so that they may be used in the computation, yet remain private.
The ingredient we need for this is secret sharing, which splits a value into three shares in such a way that if anyone sees less than the three shares, then nothing at all is revealed about the value; yet, by seeing all three shares, the value can easily be reconstructed.
To keep it simple we’ll use replicated secret sharing here, where each party receives more than one share. Concretely, private value x is split into three shares x0, x1, x2 such that x == x0 + x1 + x2. Party P0 then receives (x0, x1), P1 receives (x1, x2), and P2 receives (x2, x0). For this tutorial we’ll keep this implicit though, and simply store a sharing of x as a vector of the three shares [x0, x1, x2].
def share(x):
x0 = random.randrange(Q)
x1 = random.randrange(Q)
x2 = (x - x0 - x1) % Q
return [x0, x1, x2]
And when two or more parties agree to reveal a value to someone, they simply send their shares so that reconstruction may be performed.
def reconstruct(shares):
return sum(shares) % Q
However, if the shares are the result of one or more of the secure computations given in the subsections below, then for privacy reasons we perform a resharing before reconstructing.
def reshare(xs):
Y = [ share(xs[0]), share(xs[1]), share(xs[2]) ]
return [ sum(row) % Q for row in zip(*Y) ]
This is strictly speaking not necessary, but doing so makes it easier below to see why the protocols are secure; intuitively, it makes sure the shares look fresh, containing no information about the data that were used to compute them.
Addition and subtraction
With this we already have a way to do secure addition and subtraction: each party simply adds or subtracts its two shares. This works works since e.g. (x0 + x1 + x2) + (y0 + y1 + y2) == (x0 + y0) + (x1 + y1) + (x2 + y2), which gives the three new shares of x + y (technically speaking this should be reconstruct(x) + reconstruct(y), but it’s easier to read when implicit).
def add(x, y):
return [ (xi + yi) % Q for xi, yi in zip(x, y) ]
def sub(x, y):
return [ (xi - yi) % Q for xi, yi in zip(x, y) ]
Note that no communication is needed since these are local computations.
Multiplication
Since each party has two shares, multiplication can be done in a similar way to addition and subtraction above, i.e. by each party computing a new share based on the two it already has. Specifically, for z0, z1, and z2 as defined in the code below we have x * y == z0 + z1 + z2 (technically speaking …).
However, our invariant of each party having two shares is not satisfied, and it wouldn’t be secure for e.g. P1 simply to send z1 to P0. One easy fix is to simply share each zi as if it was a private input, and then have each party add its three shares together; this gives a correct and secure sharing w of the product.
def mul(x, y):
# local computation
z0 = (x[0]*y[0] + x[0]*y[1] + x[1]*y[0]) % Q
z1 = (x[1]*y[1] + x[1]*y[2] + x[2]*y[1]) % Q
z2 = (x[2]*y[2] + x[2]*y[0] + x[0]*y[2]) % Q
# reshare and distribute; this requires communication
Z = [ share(z0), share(z1), share(z2) ]
w = [ sum(row) % Q for row in zip(*Z) ]
# bring precision back down from double to single
v = truncate(w)
return v
One problem remains however, and as mentioned earlier this is the double precision of reconstruct(w): it is an encoding with scaling factor 10**6 * 10**6 instead of 10**6. In the unsecured setting over rationals we would fix this by a standard division by 10**6, but since we’re operating on secret shared elements in a finite field this becomes less straight-forward.
Division by a public constant, in this case 10**6, is easy enough: we simply multiply the shares by its field inverse 10**(-6). If we write reconstruct(w) == v * 10**6 + u for some v and u < 10**6, then this multiplication gives us shares of v + u * 10**(-6), where v is the value we’re after. But unlike the unsecured setting, where the leftover value u * 10**(-6) is small and removed by rounding, in the secure setting with finite field elements this meaning is lost and we need to rid of it some other way.
One way is to ensure that u == 0. Specifically, if we knew u in advance then by doing the division on w' == (w - share(u)) instead of on w, then we would get v' == v and u' == 0 as desired, i.e. without any leftover value.
The question of course is how to securely get u so we may compute w'. The details are in CS’10 but the basic idea is to first add a large mask to w, reveal this masked value to one of the parties who may then compute a masked u. Finally, this masked value is shared and unmasked, and then used to compute w'.
def truncate(a):
# map to the positive range
b = add(a, share(10**(6+6-1)))
# apply mask known only by P0, and reconstruct masked b to P1 or P2
mask = random.randrange(Q) % 10**(6+6+KAPPA)
mask_low = mask % 10**6
b_masked = reconstruct(add(b, share(mask)))
# extract lower digits
b_masked_low = b_masked % 10**6
b_low = sub(share(b_masked_low), share(mask_low))
# remove lower digits
c = sub(a, b_low)
# division
d = imul(c, INVERSE)
return d
Note that imul in the above is the local operation that multiplies each share with a public constant, is this case the field inverse of 10**6.
Secure data type
As a final step we wrap the above procedures in a custom abstract data type, allowing us to use NumPy later when we express the neural network.
class SecureRational(object):
def __init__(self, secret=None):
self.shares = share(encode(secret)) if secret is not None else []
return z
def reveal(self):
return decode(reconstruct(reshare(self.shares)))
def __repr__(self):
return "SecureRational(%f)" % self.reveal()
def __add__(x, y):
z = SecureRational()
z.shares = add(x.shares, y.shares)
return z
def __sub__(x, y):
z = SecureRational()
z.shares = sub(x.shares, y.shares)
return z
def __mul__(x, y):
z = SecureRational()
z.shares = mul(x.shares, y.shares)
return z
def __pow__(x, e):
z = SecureRational(1)
for _ in range(e):
z = z * x
return z
With this type we can operate securely on values as we would any other type:
x = SecureRational(.5)
y = SecureRational(-.25)
z = x * y
assert(z.reveal() == (.5) * (-.25))
Moreover, for debugging purposes we could switch to an unsecured type without changing the rest of the (neural network) code, or we could isolated the use of counters to for instance see how many multiplications are performed, in turn allowing us to simulate how much communication is needed.
Deep Learning
The term “deep learning” is a massive exaggeration of what we’ll be doing here, as we’ll simply play with the two and three layer neural networks from Building Safe A.I. (which in turn is from here and here) to learn basic boolean functions.
A simple function
The first experiment is about training a network to recognize the first bit in a sequence. The four rows in X below are used as the input training data, with the corresponding row in y as the desired output.
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
y = np.array([[
0,
0,
1,
1
]]).T
We’ll use the same simple two layer network, but parameterize it by a Sigmoid approximation to be defined below. Note the use of the secure function, which is a simple helper converting all values to our secure data type.
class TwoLayerNetwork:
def __init__(self, sigmoid):
self.sigmoid = sigmoid
def train(self, X, y, iterations=1000):
# initial weights
self.synapse0 = secure(2 * np.random.random((3,1)) - 1)
# training
for i in range(iterations):
# forward propagation
layer0 = X
layer1 = self.sigmoid.evaluate(np.dot(layer0, self.synapse0))
# back propagation
layer1_error = y - layer1
layer1_delta = layer1_error * self.sigmoid.derive(layer1)
# update
self.synapse0 += np.dot(layer0.T, layer1_delta)
def predict(self, X):
layer0 = X
layer1 = self.sigmoid.evaluate(np.dot(layer0, self.synapse0))
return layer1
We’ll also follow the suggested Sigmoid approximation, namely the standard Maclaurin/Taylor polynomial with five terms. I’ve used a simple polynomial evaluation here for readability, leaving room for improvement by for instance lower the number of multiplications using Horner’s method.
class SigmoidMaclaurin5:
def __init__(self):
ONE = SecureRational(1)
W0 = SecureRational(1/2)
W1 = SecureRational(1/4)
W3 = SecureRational(-1/48)
W5 = SecureRational(1/480)
self.sigmoid = np.vectorize(lambda x: W0 + (x * W1) + (x**3 * W3) + (x**5 * W5))
self.sigmoid_deriv = np.vectorize(lambda x: (ONE - x) * x)
def evaluate(self, x):
return self.sigmoid(x)
def derive(self, x):
return self.sigmoid_deriv(x)
With this in place we can train and evaluate the network (see the notebook for the details), in this case using 10,000 iterations.
# reseed to get reproducible results
random.seed(1)
np.random.seed(1)
# pick approximation
sigmoid = SigmoidMaclaurin5()
# train
network = TwoLayerNetwork(sigmoid)
network.train(secure(X), secure(y), 10000)
# evaluate predictions
evaluate(network)
Note that the training data is secured (i.e. secret shared) before inputting it to the network, and the learned weights are never revealed. The same applies to predictions, where the user of the network is the only one knowing the input and output.
Error: 0.00539115
Error: 0.0025606125
Error: 0.00167358
Error: 0.001241815
Error: 0.00098674
Error: 0.000818415
Error: 0.0006990725
Error: 0.0006100825
Error: 0.00054113
Error: 0.0004861775
Layer 0 weights:
[[SecureRational(4.974135)]
[SecureRational(-0.000854)]
[SecureRational(-2.486387)]]
Prediction on [0 0 0]: 0 (0.50000000)
Prediction on [0 0 1]: 0 (0.00066431)
Prediction on [0 1 0]: 0 (0.49978657)
Prediction on [0 1 1]: 0 (0.00044076)
Prediction on [1 0 0]: 1 (5.52331855)
Prediction on [1 0 1]: 1 (0.99969213)
Prediction on [1 1 0]: 1 (5.51898314)
Prediction on [1 1 1]: 1 (0.99946841)
And based on the evaluation above, the network does indeed seem to have learned the desired function, giving correct predictions also on unseen inputs.
Slightly more advanced function
Turning to the (negated) parity experiment next, the network cannot simply mirror one of the three components as before, but intuitively has to compute the xor between the first and second bit (the third being for the bias).
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
y = np.array([[
0,
1,
1,
0
]]).T
As explained in A Neural Network in 11 lines of Python, using the two layer network here gives rather useless results, essentially saying “let’s just flip a coin”.
Error: 0.500000005
Error: 0.5
Error: 0.5000000025
Error: 0.5000000025
Error: 0.5
Error: 0.5
Error: 0.5
Error: 0.5
Error: 0.5
Error: 0.5
Layer 0 weights:
[[SecureRational(0.000000)]
[SecureRational(0.000000)]
[SecureRational(0.000000)]]
Prediction on [0 0 0]: 0 (0.50000000)
Prediction on [0 0 1]: 0 (0.50000000)
Prediction on [0 1 0]: 0 (0.50000000)
Prediction on [0 1 1]: 0 (0.50000000)
Prediction on [1 0 0]: 0 (0.50000000)
Prediction on [1 0 1]: 0 (0.50000000)
Prediction on [1 1 0]: 0 (0.50000000)
Prediction on [1 1 1]: 0 (0.50000000)
The suggested remedy is to introduce another layer in the network as follows.
class ThreeLayerNetwork:
def __init__(self, sigmoid):
self.sigmoid = sigmoid
def train(self, X, y, iterations=1000):
# initial weights
self.synapse0 = secure(2 * np.random.random((3,4)) - 1)
self.synapse1 = secure(2 * np.random.random((4,1)) - 1)
# training
for i in range(iterations):
# forward propagation
layer0 = X
layer1 = self.sigmoid.evaluate(np.dot(layer0, self.synapse0))
layer2 = self.sigmoid.evaluate(np.dot(layer1, self.synapse1))
# back propagation
layer2_error = y - layer2
layer2_delta = layer2_error * self.sigmoid.derive(layer2)
layer1_error = np.dot(layer2_delta, self.synapse1.T)
layer1_delta = layer1_error * self.sigmoid.derive(layer1)
# update
self.synapse1 += np.dot(layer1.T, layer2_delta)
self.synapse0 += np.dot(layer0.T, layer1_delta)
def predict(self, X):
layer0 = X
layer1 = self.sigmoid.evaluate(np.dot(layer0, self.synapse0))
layer2 = self.sigmoid.evaluate(np.dot(layer1, self.synapse1))
return layer2
However, if we train this network the same way as we did before, even if only for 100 iterations, we run into a strange phenomenon: all of a sudden the errors, weights, and prediction scores explode, giving garbled results.
Error: 0.496326875
Error: 0.4963253375
Error: 0.50109445
Error: 4.50917445533e+22
Error: 4.20017387687e+22
Error: 4.38235385094e+22
Error: 4.65389939428e+22
Error: 4.25720845129e+22
Error: 4.50520005372e+22
Error: 4.31568874384e+22
Layer 0 weights:
[[SecureRational(970463188850515564822528.000000)
SecureRational(1032362386093871682551808.000000)
SecureRational(1009706886834648285970432.000000)
SecureRational(852352894255113084862464.000000)]
[SecureRational(999182403614802557534208.000000)
SecureRational(747418473813466924711936.000000)
SecureRational(984098986255565992230912.000000)
SecureRational(865284701475152213311488.000000)]
[SecureRational(848400149667429499273216.000000)
SecureRational(871252067688430631387136.000000)
SecureRational(788722871059090631557120.000000)
SecureRational(868480811373827731750912.000000)]]
Layer 1 weights:
[[SecureRational(818092877308528183738368.000000)]
[SecureRational(940782003999550335877120.000000)]
[SecureRational(909882533376693496709120.000000)]
[SecureRational(955267264038446787723264.000000)]]
Prediction on [0 0 0]: 1 (41452089757570437218304.00000000)
Prediction on [0 0 1]: 1 (46442301971509056372736.00000000)
Prediction on [0 1 0]: 1 (37164015478651618328576.00000000)
Prediction on [0 1 1]: 1 (43504970843252146044928.00000000)
Prediction on [1 0 0]: 1 (35282926617309558603776.00000000)
Prediction on [1 0 1]: 1 (47658769913438164484096.00000000)
Prediction on [1 1 0]: 1 (35957624290517111013376.00000000)
Prediction on [1 1 1]: 1 (47193714919561920249856.00000000)
The reason for this is simple, but perhaps not obvious at first (it wasn’t for me). Namely, while the (five term) Maclaurin/Taylor approximation of the Sigmoid function is good around the origin, it completely collapses as we move further away, yielding results that are not only inaccurate but also of large magnitude. As a result we quickly blow any finite number representation we may use, even in the unsecured setting, and start wrapping around.
Technically speaking it’s the dot products on which the Sigmoid function is evaluated that become too large, which as far as I understand can be interpreted as the network growing more confident. In this light, the problem is that our approximation doesn’t allow it to get confident enough, leaving us with poor accuracy.
How this is avoided in Building Safe A.I. is not clear to me, but my best guess is that a combination of lower initial weights and an alpha update parameter makes it possible to avoid the issue for a low number of iterations (less then 300 it seems). Any comments on this are more than welcome.
Approximating Sigmoid
So, the fact that we have to approximate the Sigmoid function seems to get in the way of learning more advanced functions. But since the Maclaurin/Taylor polynomial is accurate in the limit, one natural next thing to try is to use more of its terms.
As shown below, adding terms up to the 9th degree instead of only up to the 5th actually gets us a big further, but far from enough. Moreover, when the collapse happens, it happens even faster.
Error: 0.49546145
Error: 0.4943132225
Error: 0.49390536
Error: 0.50914575
Error: 7.29251498137e+22
Error: 7.97702462371e+22
Error: 7.01752029207e+22
Error: 7.41001528681e+22
Error: 7.33032620012e+22
Error: 7.3022511184e+22
...
Alternatively one may instead remove terms in an attempt to contain the collapse better, and e.g. only use terms up to the 3rd degree. This actually helps a bit and allows us to train for 500 iterations instead of 100 before collapsing.
Error: 0.4821573275
Error: 0.46344183
Error: 0.4428059575
Error: 0.4168092675
Error: 0.388153325
Error: 0.3619875475
Error: 0.3025045425
Error: 0.2366579675
Error: 0.19651228
Error: 0.1748352775
Layer 0 weights:
[[SecureRational(1.455894) SecureRational(1.376838)
SecureRational(-1.445690) SecureRational(-2.383619)]
[SecureRational(-0.794408) SecureRational(-2.069235)
SecureRational(-1.870023) SecureRational(-1.734243)]
[SecureRational(0.712099) SecureRational(-0.688947)
SecureRational(0.740605) SecureRational(2.890812)]]
Layer 1 weights:
[[SecureRational(-2.893681)]
[SecureRational(6.238205)]
[SecureRational(-7.945379)]
[SecureRational(4.674321)]]
Prediction on [0 0 0]: 1 (0.50918230)
Prediction on [0 0 1]: 0 (0.16883382)
Prediction on [0 1 0]: 0 (0.40589161)
Prediction on [0 1 1]: 1 (0.82447640)
Prediction on [1 0 0]: 1 (0.83164009)
Prediction on [1 0 1]: 1 (0.83317334)
Prediction on [1 1 0]: 1 (0.74354671)
Prediction on [1 1 1]: 0 (0.18736629)
However, the errors and predictions are poor, and there is little room left for increasing the number of iterations (it collapses around 550 iterations).
Interpolation
An alternative approach is to drop the standard approximation polynomial and instead try interpolation over an interval. The main parameter here is the max degree of the polynomial, which we want to keep somewhat low for efficiency, but the precision of the coefficients is also relevant.
# function we wish to approximate
f_real = lambda x: 1/(1+np.exp(-x))
# interval over which we wish to optimize
interval = np.linspace(-10, 10, 100)
# interpolate polynomial of given max degree
degree = 10
coefs = np.polyfit(interval, f_real(interval), degree)
# reduce precision of interpolated coefficients
precision = 10
coefs = [ int(x * 10**precision) / 10**precision for x in coefs ]
# approximation function
f_interpolated = np.poly1d(coefs)
By plotting this polynomial (red line) together with the standard approximations we see a hope for improvement: we cannot avoid collapsing at some point, but it is now on significantly larger values.
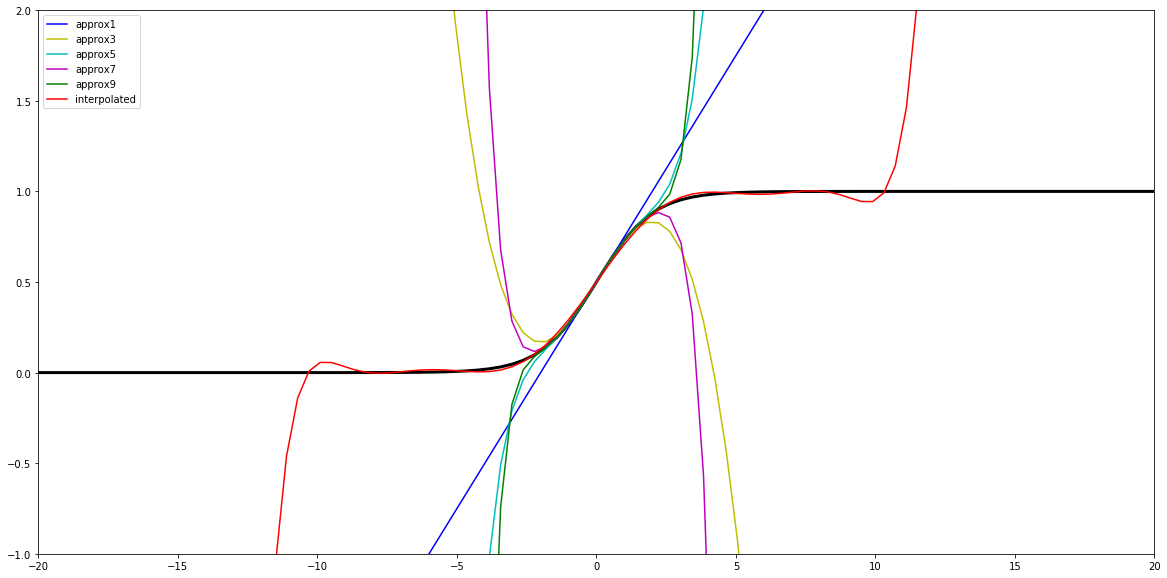
Of course, we could also experiment with other degrees, precisions, and intervals as shown below, yet for our immediate application the above set of parameters seem sufficient.

So, returning to our three layer network, we define a new Sigmoid approximate:
class SigmoidInterpolated10:
def __init__(self):
ONE = SecureRational(1)
W0 = SecureRational(0.5)
W1 = SecureRational(0.2159198015)
W3 = SecureRational(-0.0082176259)
W5 = SecureRational(0.0001825597)
W7 = SecureRational(-0.0000018848)
W9 = SecureRational(0.0000000072)
self.sigmoid = np.vectorize(lambda x: \
W0 + (x * W1) + (x**3 * W3) + (x**5 * W5) + (x**7 * W7) + (x**9 * W9))
self.sigmoid_deriv = np.vectorize(lambda x:(ONE - x) * x)
def evaluate(self, x):
return self.sigmoid(x)
def derive(self, x):
return self.sigmoid_deriv(x)
… and rerun the training:
# reseed to get reproducible results
random.seed(1)
np.random.seed(1)
# pick approximation
sigmoid = SigmoidInterpolated10()
# train
network = ThreeLayerNetwork(sigmoid)
network.train(secure(X), secure(y), 10000)
# evaluate predictions
evaluate(network)
And now, despite running for 10,000 iterations, no collapse occurs and the predictions improve, with only one wrong prediction on [0 1 0].
Error: 0.0384136825
Error: 0.01946007
Error: 0.0141456075
Error: 0.0115575225
Error: 0.010008035
Error: 0.0089747225
Error: 0.0082400825
Error: 0.00769687
Error: 0.007286195
Error: 0.00697363
Layer 0 weights:
[[SecureRational(3.208028) SecureRational(3.359444)
SecureRational(-3.632461) SecureRational(-4.094379)]
[SecureRational(-1.552827) SecureRational(-4.403901)
SecureRational(-3.997194) SecureRational(-3.271171)]
[SecureRational(0.695226) SecureRational(-1.560569)
SecureRational(1.758733) SecureRational(5.425429)]]
Layer 1 weights:
[[SecureRational(-4.674311)]
[SecureRational(5.910466)]
[SecureRational(-9.854162)]
[SecureRational(6.508941)]]
Prediction on [0 0 0]: 0 (0.28170669)
Prediction on [0 0 1]: 0 (0.00638341)
Prediction on [0 1 0]: 0 (0.33542098)
Prediction on [0 1 1]: 1 (0.99287968)
Prediction on [1 0 0]: 1 (0.74297185)
Prediction on [1 0 1]: 1 (0.99361066)
Prediction on [1 1 0]: 0 (0.03599433)
Prediction on [1 1 1]: 0 (0.00800036)
Note that the score for the wrong case is not entirely off, and is somewhat distinct from the correctly predicted zeroes. Running for another 5,000 iterations didn’t seem to improve this, at which point we get close to the collapse.
Conclusion
The focus of this tutorial has been on a simple secure multi-party computation protocol, and while we haven’t explicitly addressed the initial claim that it is computationally more efficient than homomorphic encryption, we have still seen that it is indeed possible to achieve private machine learning using very basic operations.
Perhaps more critically, we haven’t measured the amount of communication required to run the protocols, which most significantly boils down to a few messages for each multiplication. To run any extensive computation using the simple protocols above it is clearly preferable to have the three parties connected by a high-speed local network, yet more advanced protocols not only reduce the amount of data sent back and forth, but also improve other properties such as the number of rounds (down to a small constant in the case of garbled circuits).
Finally, we have mostly treated the protocols and the machine learning processes orthogonally, letting the latter use the former only in a black box fashion except for computing the Sigmoid. Further adapting one to the other requires expertise in both domains but may yield significant improvements in the overall performance.